📌 Встреча клуба Data Science 5 июня
🔻В понедельник 5 июня состоялась очередная встреча клуба Data Science. Мы обсудили разметку текстов, которую проводим в рамках проекта КДС-П-1. По результатам обсуждений мы пришли к следующим выводам:
1) нужен контекст - многие комментарии являются ответами на другие высказывания, присутствие которых может сильно помочь разметке
2) высказывания пользователей многогранны - зачастую их мнения сводятся не просто к альтернативам за маски / против масок, а содержат сложные системы убеждений. В связи с этим было решено в рамках разметки попытаться построить базис из основных убеждений, а далее высказывание каждого пользователя раскладывать по ним. То есть разметка будет иметь форму таблицы, где строки - пользователи, а столбцы - базовые убеждения. Если пользователь высказался (например, про чипы) - то в соответствующей ячейке ставим целое число от -2 до 2. (-2 - не верит совсем, -1 - маловероятно, что верит, 0 - нейтрально, 1 - немного верит, 2 - уверен, что такой заговор есть).
3) Если высказывание с иронией, то ставим какую-нибудь метку, например звездочку.
4) Для разметок текстов про маски и конспирологию базисы убеждений могут быть разными, но иметь пересечения. Я, когда размечал конспирологию, встречал и высказывания про отношение к маскам. Потом мы эти два базиса сольем воедино.
5) Дмитрий Алексеевич через некоторое время подготовит обновленную версию тех же 100 комментариев, но уже с контекстом. Контекст тоже нужно размечать.
📌 Встреча клуба Data Science 22 мая
🔻В понедельник 22 мая состоялась очередная встреча клуба Data Science. Был заслушан ряд докладов студентов Дарьяны Владимировны Лемтюжниковой, которые готовятся к защите выпускных квалификационных работ:
1) Письменский Д.В. — "Классификация мнений о вакцинации с использованием методов машинного обучения"
2) Шавандрин Ф.М. — "Классификация мнений о вакцинации с использованием методов машинного обучения"
3) Демьяненко А.Е. — "Анализ художественных произведений с помощью методов искусственного интеллекта"
4) Стрыгин Д.Д. — "Поиск символов на цифровых изображениях голландских натюрмортов"
5) Козловский А.М. — "Мониторинг развития детей младшего возраста по нарративу с помощью NLP"
📌 Встреча клуба Data Science 15 мая
🔻В понедельник 15 мая состоялась очередная встреча клуба Data Science.
Мы перешли к следующей фазе нашего проекта (название я пока не придумал - можно будет вместе сгенерировать) - разметке корпуса текстов про Covid-19.
Встреча носила организационный характер - была сформирована команда, мы обменялись нужными контактами и установили протокол взаимодействия.
📌Хочу отметить, что формат наших дальнейших встреч не будет ограничиваться этим проектом - желающие всегда могут рассказать о своих исследованиях в области машинного обучения и анализа данных, или же предложить тему для дискуссии.
📌После обсуждений вопросов разметки прошел ряд выступлений студентов Дарьяны Владимировны Лемтюжниковой по тематике анализа текстов.
📌 Встреча клуба Data Science 3 апреля
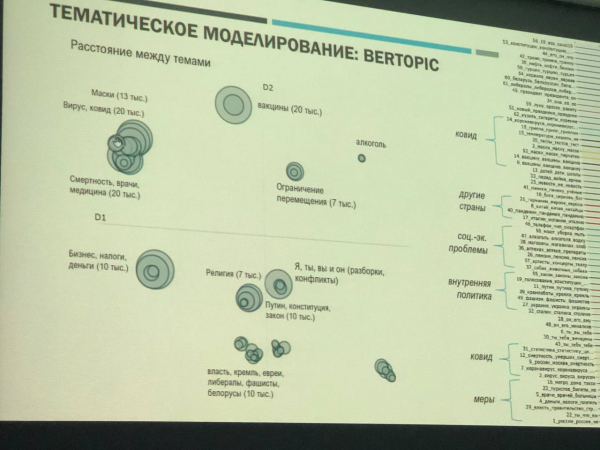
🔻В понедельник 3 апреля 2023 года состоялась очередная встреча клуба Data Science. Разговор шел про тематическое моделирование - важный раздел теории обработки естественных языков, основная цель которого - выявить список тем, наиболее выпукло представленных в заданном наборе документов.
▪️ Спикером мероприятия выступил наш коллега Дмитрий Алексеевич Губанов - специалист в области теории управления социально-экономическими системами, а также эксперт в области методов машинного обучения и, в частности, анализа естественных языков.
▪️ Доклад Дмитрия был посвящен анализу крупномасштабного (~1.5 млн документов) корпуса текстов из социальной сети ВКонтакте относительно тематики пандемии коронавируса.
▪️ Представленное исследование является частью проекта по анализу общественного мнения в 2020-2021 гг. Далее планируется начать подготовку данных (разметка, предобработка) относительно выбранного списка тем, после чего вести разработку предиктивных моделей.
❗️ Приглашаем всех желающих присоединиться к проекту!!!
❗️ Презентация выступления
❗️ Ссылка на телеграм-канал

📌 Встреча клуба Data Science 13 февраля
Первая после новогоднего перерыва встреча была посвящена нашумевшей в последнее время языковой модели ChatGPT. Поговорили о ее возможностях, о том как она на самом деле работает и как проходило ее обучение.
Спикер - Илья Кудинов, математик лаборатории 68.
P.S.: по результатам встречи наш коллега Артем Голев (младший научный сотрудник лаборатории 46) предложил использовать ChatGPT для того, чтобы составить отчет о прошедней встрече. Ответ ChatGPT:

Дайджест
Секция посвящена актуальным вопросам машинного обучения, анализа данных и имитационного моделирования – вопросам, играющим огромную роль в устойчивом развитии современного общества. В рамках секции работает семинар, участники которого знакомятся с современными методами и подходами науки о данных и ее практическими приложениями в самых различных предметных областях.

Контакты
Козицин И.В., лаб. 57, e-mail: kozitsin.ivan@mail.ru
Телеграм-канал Data Science